Pendant longtemps, l’objectif principal d’un Data Scientist a été de trouver la meilleure recette algorithmique pour répondre à un problème métier donné. Pour faciliter cette phase de prototypage, de nombreux outils ont vu le jour comme les librairies open-source et les plateformes de Data Science ; ces dernières allant même jusqu’à proposer une expérience no-code.
·
Apr 14, 2022
Cependant, un aspect essentiel d’un projet d’intelligence artificielle a trop longtemps été ignoré : l’industrialisation. Il ne faut pas perdre de vue que seule une IA en production, c’est-à-dire un système dont les résultats (prévisions, recommandations, etc.) sont mis à la disposition de leurs utilisateurs finaux, peut permettre des gains significatifs de productivité pour les entreprises.
Selon Gartner, près de 85% des projets d’IA échouent à passer en production. Et pour ceux qui y parviennent le constat est sans appel : les coûts sont importants et les contraintes nombreuses. Mais alors qu’est-ce qui explique ce "mur de l’industrialisation" ?
Déployer et redéployer le modèle de Machine Learning
Une fois la recette algorithmique validée lors du prototypage, il devient nécessaire de confronter le modèle aux données dynamiques, arrivant en temps réel. L'environnement de production devra disposer d’un connecteur de données (bases de données, API web, espaces cloud de stockage,...) stable et performant.
Les résultats de prototypage sont alors mis au défi des données en temps réel, trop souvent différentes de celles de prototypage. Il convient donc de réviser la méthode.
Passée cette première épreuve, le code doit gagner en maintenabilité et en performance pour passer en production en tenant la charge et supporter chaque évolution. Cette reprise du code (refactoring) est une étape nécessaire ; une optimisation trop en amont serait contre productive, réduisant l’agilité du prototypage. L’environnement de mise en production doit se prêter à cette conversion des méthodes entre prototypage et production.
"Le passage à l’échelle et l’intégration aux systèmes d’information de production nécessitent des compétencesspécifiques démultipliant le coût initial du projet."
Le passage à l’échelle et l’intégration aux systèmes d’information de production nécessitent des compétences spécifiques et très demandées - comprendre chères - comme des ML Engineers / Devops / Développeurs, démultipliant le coût initial du projet. Une approche manuelle de ces étapes, non capitalisée, rend la mise en production possible en théorie mais chère, longue et périlleuse d’une mise en production à l’autre.
Les difficultés deviennent encore plus conséquentes quand il s’agit de modifier et mettre à jour la recette algorithmique, rarement figée une fois passée en production. Chaque redéploiement sera très chronophage, car obligeant à reprendre les étapes de mise en production. Ainsi, les évolutions seront très lourdes à redéployer, ce qui peut inciter à garder en production des solutions inadaptées ou consacrer énormément de temps aux redéploiements.
Les frictions des mises en production aboutissent souvent à des abandons des solutions : trop lourdes, trop risquées, trop chronophages.
Suivre la production
Une fois le modèle déployé, une supervision permanente est nécessaire pour permettre aux équipes Data d’être alertées sur les dysfonctionnements du service, si possible en amont ; de les diagnostiquer et de les corriger.
Deux types de dysfonctionnements différents peuvent apparaître.
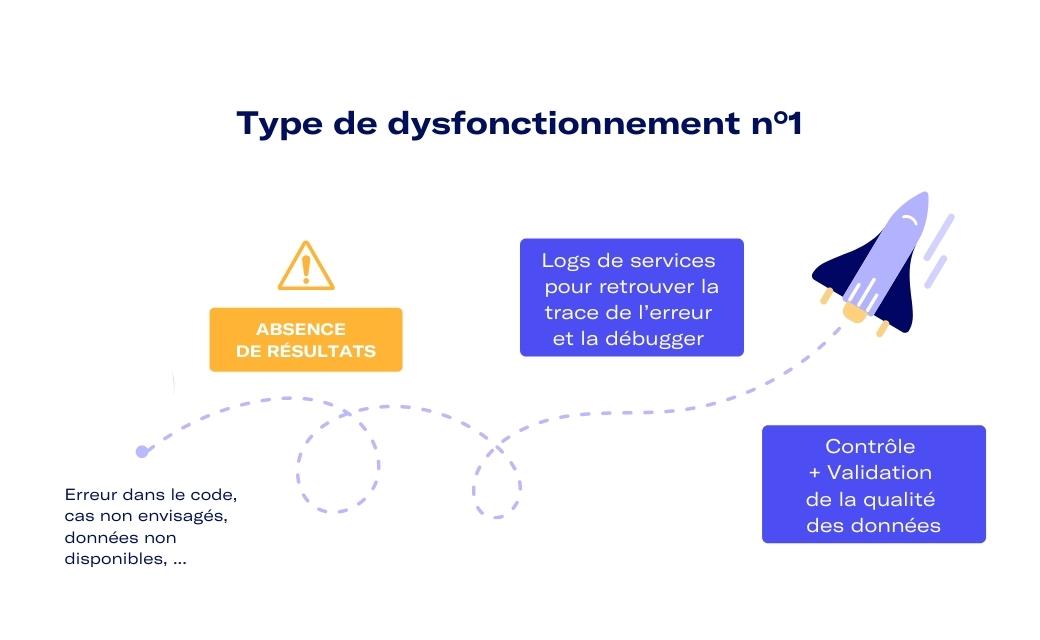
Premier dysfonctionnement possible : les utilisateurs ne reçoivent plus de résultats. Cela peut provenir d’une erreur dans le code, d’un cas non-envisagé, d’une indisponibilité de la donnée source…
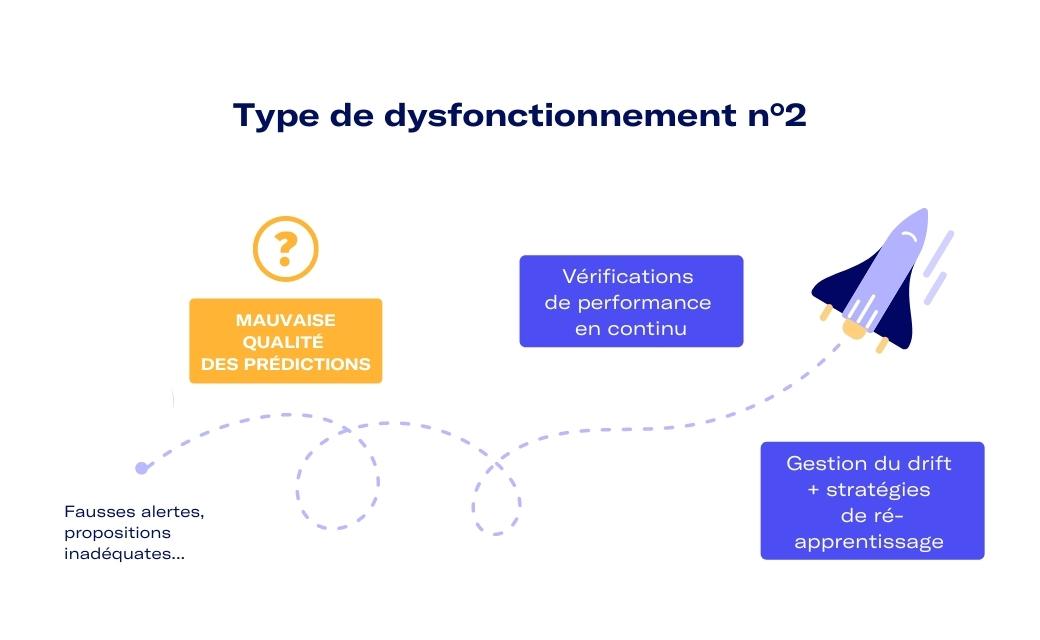
Deuxième dysfonctionnement possible, plus spécifique aux services de Machine Learning : les utilisateurs reçoivent des prévisions mais celles-ci sont de mauvaise qualité. C’est le cas par exemple quand un service de maintenance prédictive lève trop de fausses alertes ou un moteur de recommandations envoie des propositions inadéquates ou peu intéressantes. Dans cette situation, le système est opérationnel d’un point de vue logiciel, mais pas d’un point de vue métier, ce qui peut entraîner une moins bonne adoption de l’IA par perte de confiance dans ses résultats.
Pour le premier cas de dysfonctionnement, avoir des logs du service pour être capable de retrouver la trace de l’erreur et la débugger sera clé. L’observabilité des opérations est ici capitale. Elle réduit drastiquement les temps d’identification et de correction du service.
De plus, pour prévenir les interruptions de services liées aux données d’entrée, les Data Scientists ou ML Engineers doivent mettre en oeuvre des contrôles et validations de qualité des données (par exemple vérifier les types de données, les pertes de données, les données manquantes, les valeurs aberrantes, les changements de noms dans les champs des données, …).
"L’observabilité des opérations est ici capitale. Elle réduit drastiquement les temps d’identification et de correction du service."
Pour le second type de dysfonctionnement, cela s’avère beaucoup moins évident à détecter. Identifier une perte de performance mathématique d’un modèle de Machine Learning nécessite des stratégies plus complexes de prise en charge. Un enjeu principal est de mettre en place des vérifications de performance en continu et lever des alertes lorsque cette dernière diminue. On parle ici de gestion de la dérive (drift), de stratégies de ré-apprentissage et dans certains cas de modification des modèles.
Pour accompagner le déploiement et la maintenance, les équipes Data auront besoin entre autres d’outils de gestion des versions (versioning) et de suivi d’expériences (tracking) : pour pouvoir revenir à n’importe quel état antérieur (avec la bonne version des données, du code, du modèle…) de façon simple et sûre et comparer les modèles entre eux.
La route des mises en production est longue et sinueuse pour que les services de Machine Learning délivrent de la valeur sur le long terme.
Optimisation de la recette algorithmique, gestion de l’environnement de production, reprise de code, mise à jour des modèles, gestion de la dérive, ré-entraînement, etc. Autant d’étapes clés et de points de frictions qui peuvent mettre en péril l’industrialisation d’un projet d’IA.
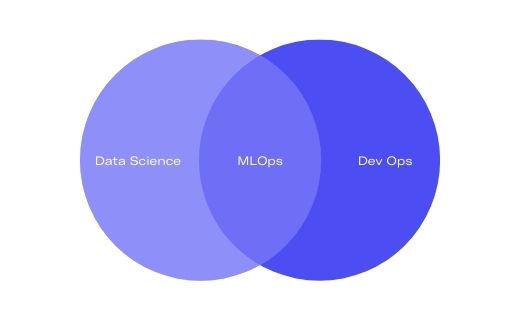
L’ensemble de ces fonctions se situe au croisement des champs de compétence d’un Data Scientist et d’un DevOps.
C’est pourquoi l’émergence et l’adoption du MLOps (Machine Learning Operations) sont si importantes : il fournit enfin aux équipes Data une méthodologie et des outils pour franchir sereinement le mur de l’industrialisation.
En permettant de surcroît une diminution des coûts de production et une augmentation de la fiabilité des résultats, le MLOps a tout pour faire connaître à l’intelligence artificielle son véritable essor.
Subscribe to our Newsletter
Stay up to date with the latest news, articles, and updates. Subscribe now!
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.